Simple Q Learning 기법에서 문제점과 Exploit & Exploration
여기까지의 실습으로 Q 러닝으로 어떻게 문제를 해결할 수 있는지 알아보았습니다. 하지만 기존 Q 러닝은 항상 학습된 길로만 향하기 때문에 최적이 아닌 길로 한번 학습되면 최적의 길은 찾지 못할 가능성이 있습니다.
예를 들어 다음과 같이 길이 학습되어 있다고 가정해보겠습니다.
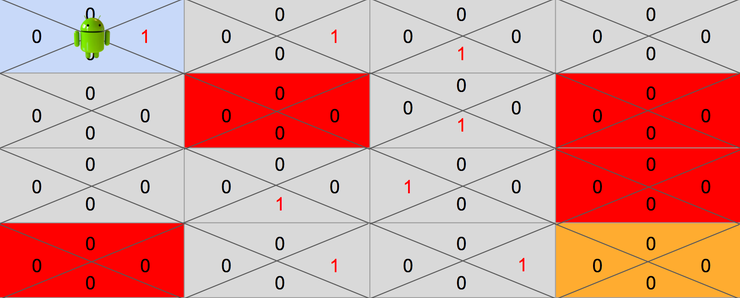
위와같이 학습될 가능성도 충분히 있습니다. 이렇게 되면 기존 알고리즘은 항상 Q 테이블에서 제공하는 최대보상의 액션만 취하기 때문에 최적의 길이 아닌 경로로만 목적지에 도달하게 됩니다.
최적의 길을 찾기 위해서는 가끔씩은 Q 의 최대 보상값이 아닌 길로도 탐색을 해야할 필요가 있습니다. 이렇게 Q에서 알려준 방법대로 선택하는 것을 Exploit, 새로운 길로 탐색하는 것을 Exploration 이라고 부르고 그것을 선택하는 방법을 Exploit & Exploration 알고리즘이라고 합니다.
다음 장부터 Exploit & Exploration 를 구현하기 위한 방법중 E-Greedy Decaying 방법과 Random Noise 기법에 대해 얘기해보겠습니다.