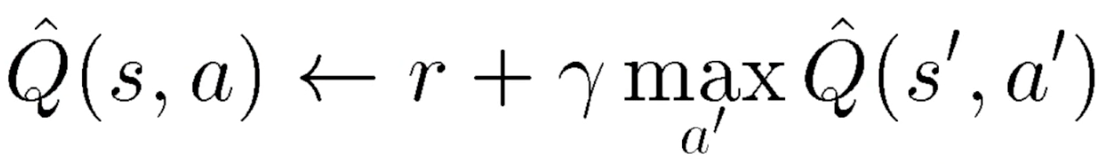담당자: 조현수
- Discounted Reward 개념 소개
- Discounted Reward 를 적용하기 위해 Q 업데이트 알고리즘이 어떻게 바뀌는지 설명
Discounted Reward
앞서 Simple Q Learning이 가진 문제점(항상 학습된 길로만 향하는)을 해결하기 위해서, Exploit & Exploration 알고리즘을 사용하여 최적의 길을 찾는 방법을 설명하였습니다.
Exploit & Exploration을 통해 여러가지 길들을 찾았다고 가정을 해보면 아래와 같이 학습이 되어 있을 수 있습니다.
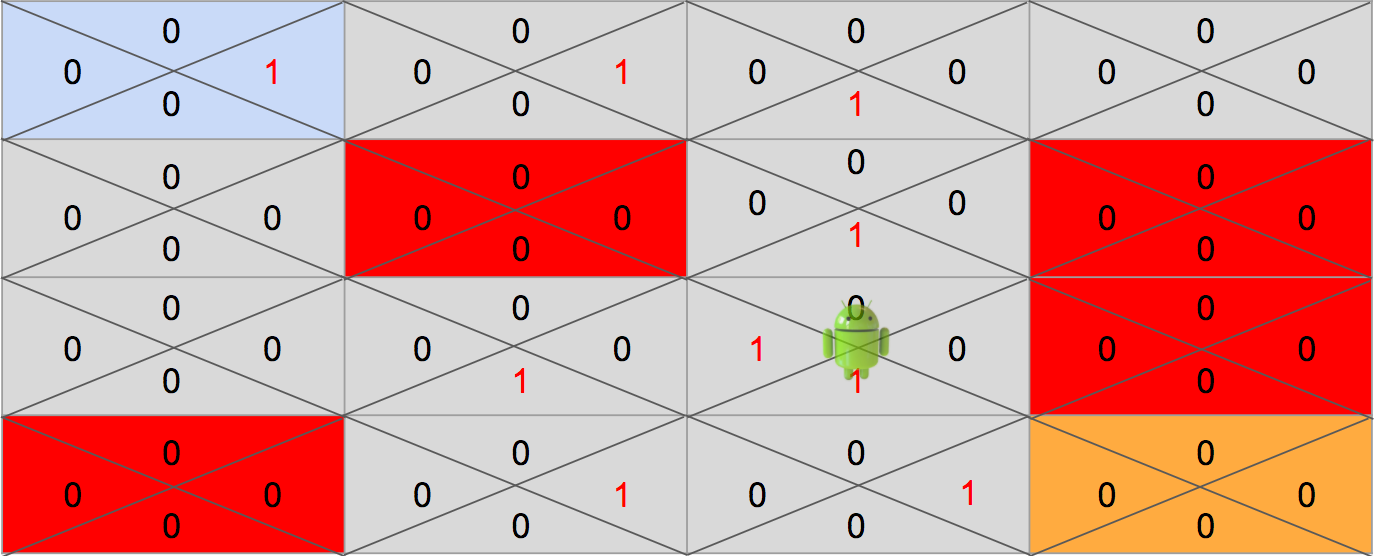 위와 같이 학습이 된 상태를 놓고 볼때, 현재 에이전트가 위치한 곳에서는 어느 방향으로 이동을 하는 것이 좋을지 알 수 가 없습니다. 왜냐하면 에이전트 입장에선 Left로 이동해도 Down으로 이동해도 동일한 값을 얻기 때문입니다.
위와 같이 학습이 된 상태를 놓고 볼때, 현재 에이전트가 위치한 곳에서는 어느 방향으로 이동을 하는 것이 좋을지 알 수 가 없습니다. 왜냐하면 에이전트 입장에선 Left로 이동해도 Down으로 이동해도 동일한 값을 얻기 때문입니다.
그래서 이러한 문제를 해결하기 위한 방법이 바로 Discounted Reward 입니다.
(내용 추가 예정)